HTTP协议详解
本博客所有文章采用的授权方式为 自由转载-非商用-非衍生-保持署名 ,转载请务必注明出处,谢谢。
声明:
本博客欢迎转发,但请保留原作者信息!
博客地址:任志帆的博客;
内容系本人学习、研究和总结,如有雷同,实属荣幸!
- HTTP简介
- 浏览网页是HTTP的主要应用,但是这并不代表HTTP就只能应用于网页的浏览。HTTP是一种协议,只要通信的双方都遵守这个协议,HTTP就能有用武之地。比如咱们常用的QQ,迅雷这些软件,都会使用HTTP协议(还包括其他的协议)。
- HTTP特点
- HTTP工作流程
- HTTP之请求消息Request
- HTTP之响应消息Response
- HTTP之状态码
- HTTP请求方法
- GET和POST的区别
HTTP协议详解
HTTP简介
-
HTTP协议,即超文本传输协议(Hypertext transfer protocol)。是一种详细规定了浏览器和万维网(WWW = World Wide Web)服务器之间互相通信的规则,通过因特网传送万维网文档的数据传送协议。
-
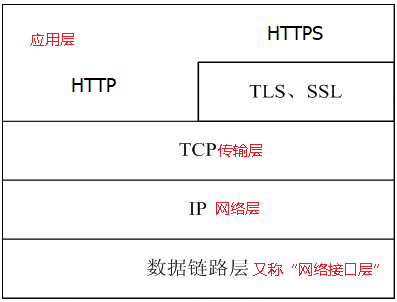
HTTP协议作为TCP/IP模型中应用层的协议也不例外。HTTP协议通常承载于TCP协议之上,有时也承载于TLS或SSL协议层之上,这个时候,就成了我们常说的HTTPS。如下图:
-
HTTP是一个应用层协议,由请求和响应构成,是一个标准的客户端服务器模型。HTTP是一个无状态的协议。
-
HTTP默认的端口号为80,HTTPS的端口号为443。
-
浏览网页是HTTP的主要应用,但是这并不代表HTTP就只能应用于网页的浏览。HTTP是一种协议,只要通信的双方都遵守这个协议,HTTP就能有用武之地。比如咱们常用的QQ,迅雷这些软件,都会使用HTTP协议(还包括其他的协议)。
HTTP特点
-
简单快速:客户向服务器请求服务时,只需传送请求方法和路径。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快
-
灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记
-
HTTP 0.9和1.0使用非持续连接:限制每次连接只处理一个请求,服务器处理完客户的请求,并收到客户的应答后,即断开连接。HTTP 1.1使用持续连接:不必为每个web对象创建一个新的连接,一个连接可以传送多个对象,采用这种方式可以节省传输时间
-
无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快
-
支持B/S及C/S模式。
HTTP工作流程
每个万维网的网点都有一个服务器进程,它不断的监听TCP端口80,以便发现是否有浏览器向它发出连接请求,一旦坚挺到连接建立请求,就通过三次握手建立TCP连接,然后浏览器会向服务器发出浏览某个页面的请求,服务器接着返回所请求的页面作为响应,然后TCP连接就被释放了
这些响应和请求报文都遵循一定的格式,这就是HTTP协议所规定的
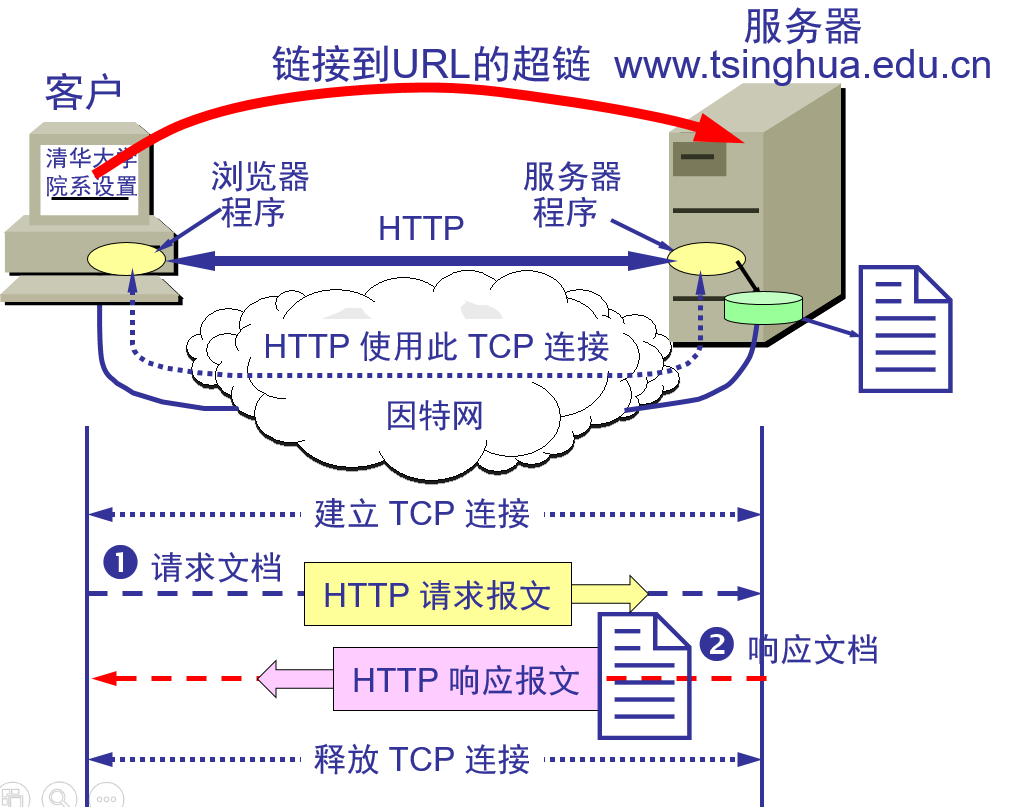
点击一个URL会发生的一系列事件
(1) 浏览器分析超链指向页面的 URL。
(2) 浏览器向 DNS 请求解析 www.tsinghua.edu.cn 的 IP 地址。
(3) 域名系统 DNS 解析出清华大学服务器的 IP 地址。
(4) 浏览器与服务器建立 TCP 连接
(5) 浏览器发出取文件命令:如 GET /chn/yxsz/index.htm。
(6) 服务器给出响应,把文件 index.htm 发给浏览器。
(7) TCP 连接释放。
(8) 浏览器显示“清华大学院系设置”文件 index.htm 中的所有文本
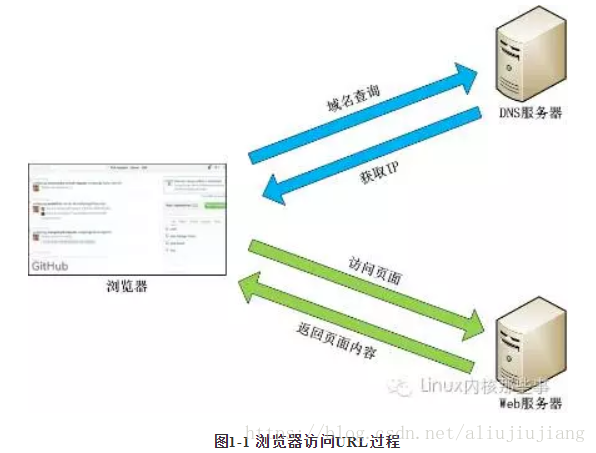
代理服务器
代理服务器(proxy server)又称为万维网高速缓存(Web cache),它代表浏览器发出HTTP请求。代理服务器把最近的一些请求和响应暂存在本地磁盘中。当与暂时存放的请求相同的新请求到达时,万维网高速缓存就把暂存的响应发送出去,而不需要按URL的地址再去因特网访问该资源
在不使用代理服务器时,所有的主机都需要与因特网上的服务器建立连接,会使得链路负载比较大;使用代理服务器可以降低链路的压力。
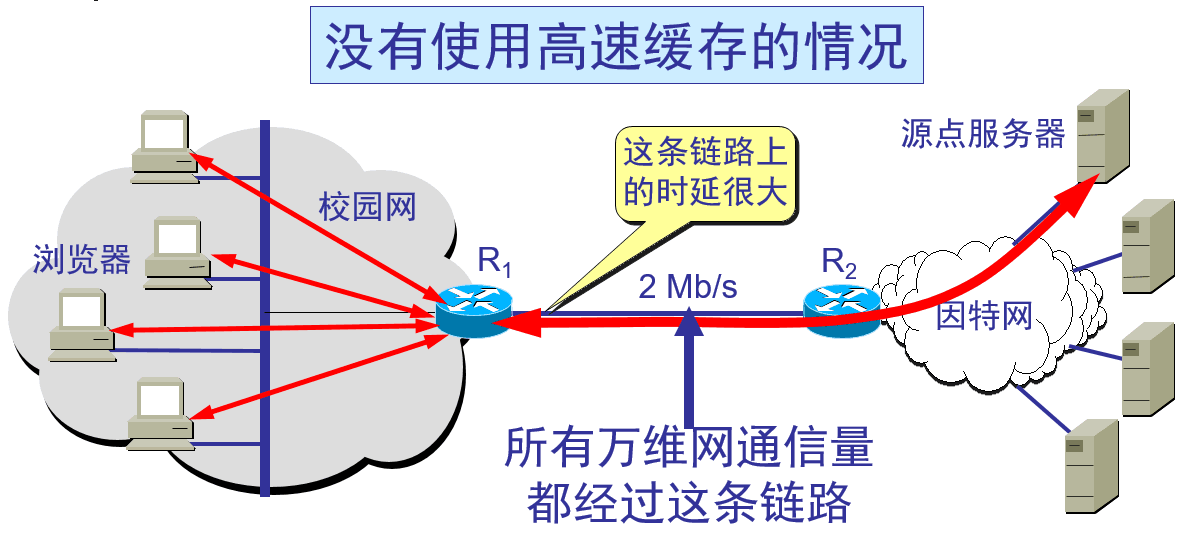
- 使用高速缓存的情况:
(1)浏览器访问因特网的服务器时,要先与校园网的高速缓存建立TCP连接,并向高速缓存发出HTTP请求报文
(2)若高速缓存已经存放了所请求的对象,则将此对象放入HTTP响应报文中返回给浏览器。
(3)否则,高速缓存就代表发出请求的用户浏览器,与因特网上的源点服务器建立TCP连接,并发送HTTP请求报文。
(4)源点服务器将所请求的对象放在HTTP响应报文中返回给校园网的高速缓存。
(5)高速缓存收到此对象后,先复制在其本地存储器中(为今后使用),然后再将该对象放在HTTP响应报文中,通过已建立的TCP连接,返回给请求该对象的浏览器。
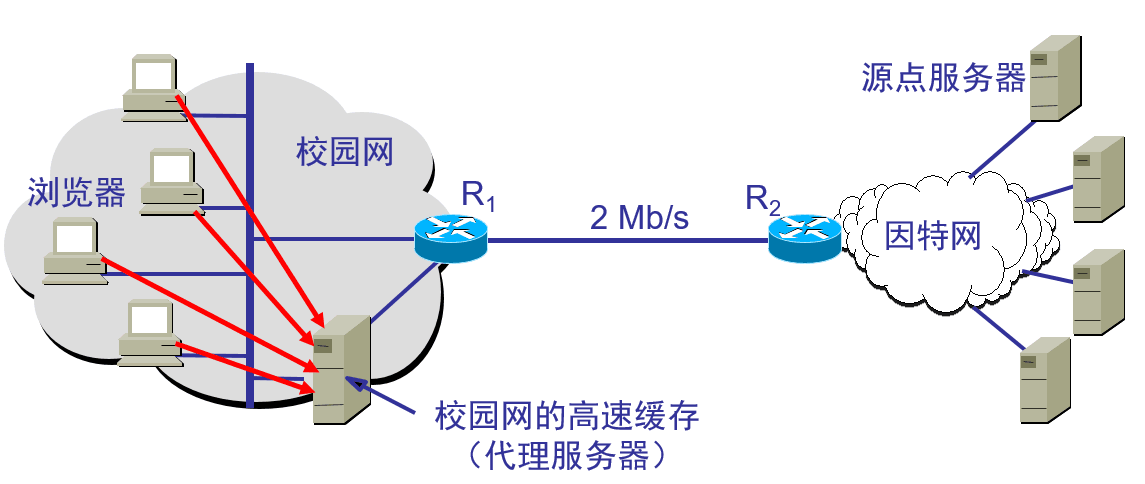
总结起来,代理服务器有时作为服务器接受来自浏览器的HTTP请求,有时又会作为客户去向因特网上的原点服务器发送HTTP请求,具有双重身份。同时,由于使用了高速缓存,相当大的一部分通信量都限制在了校园网的内部,减小了网络链路的负载
HTTP之请求消息Request
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:
请求行、请求头部、空行和请求数据四个部分组成。
Get请求例子
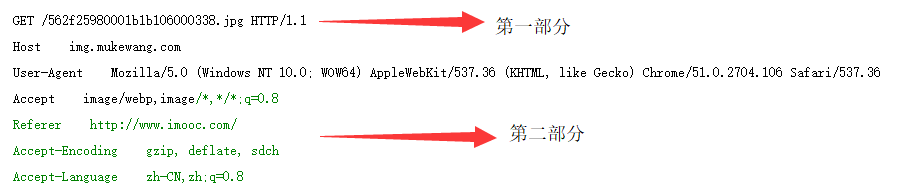
第一部分:请求行,用来说明请求类型,要访问的资源以及所使用的HTTP版本,. GET说明请求类型为GET,[/562f25980001b1b106000338.jpg]为要访问的资源,该行的最后一部分说明使用的是HTTP1.1版本。
第二部分:,请求头部,紧接着请求行(即第一行)之后的部分,用来说明服务器要使用的附加信息, 从第二行起为请求头部,HOST将指出请求的目的地.User-Agent,服务器端和客户端脚本都能访问它,它是浏览器类型检测逻辑的重要基础.该信息由你的浏览器来定义,并且在每个请求中自动发送等等
第三部分:,空行,请求头部后面的空行是必须的, 即使第四部分的请求数据为空,也必须有空行。
第四部分:,请求数据也叫主体,可以添加任意的其他数据,。 这个例子的请求数据为空。
POST请求例子

第一部分:请求行,第一行明了是post请求,以及http1.1版本。 第二部分:请求头部,第二行至第六行。 第三部分:空行,第七行的空行。 第四部分:请求数据,第八行。
HTTP之响应消息Response
一般情况下,服务器接收并处理客户端发过来的请求后会返回一个HTTP的响应消息。
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。
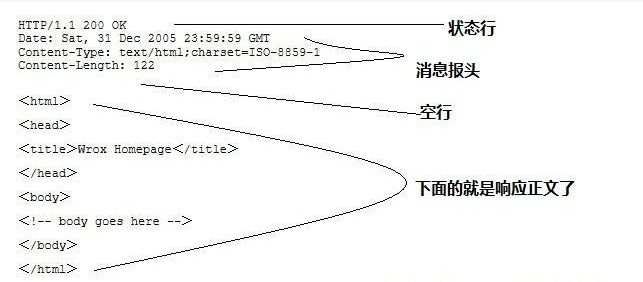
第一部分:状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成。 第一行为状态行,(HTTP/1.1)表明HTTP版本为1.1版本,状态码为200,状态消息为(ok)
第二部分:消息报头,用来说明客户端要使用的一些附加信息 第二行和第三行和第四行为消息报头, Date:生成响应的日期和时间;Content-Type:指定了MIME类型的HTML(text/html),编码类型是ISO-8859-1
第三部分:空行,消息报头后面的空行是必须的 第四部分:响应正文,服务器返回给客户端的文本信息。
空行后面的html部分为响应正文。
HTTP之状态码
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
1xx:指示信息–表示请求已接收,继续处理
2xx:成功–表示请求已被成功接收、理解、接受
3xx:重定向–要完成请求必须进行更进一步的操作
4xx:客户端错误–请求有语法错误或请求无法实现
5xx:服务器端错误–服务器未能实现合法的请求
最无耻的 HTTP 常用状态码图解
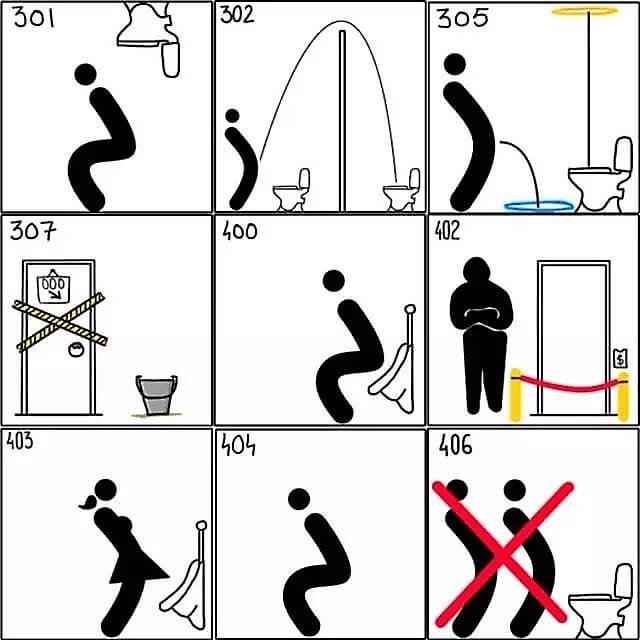
301 永久移动位置,被请求的资源已经被永久性的转移了位置
302 您请求的资源现在需要临时通过其他的 URI 来获取
305 使用代理,被请求的资源必须通过指定的代理才能访问到
307 临时跳转。被请求的资源在临时从不同的URL响应请求
400 请求错误
402 该状态码是为了将来可能的需求而预留的,比如可能用于一些数字货币或者是微支付
403 禁止访问。服务器已经理解请求,但是拒绝执行它
404 找不到对象。请求失败,资源不存在,程序员找对象简直是宇宙谜题
406 不可接受的。请求的资源的内容特性无法满足请求头中的条件,因而无法生成响应实体
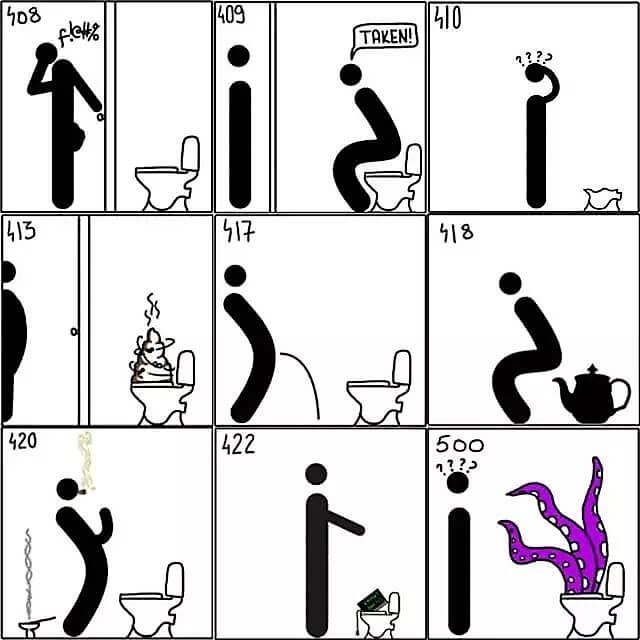
408 请求超时,请活活憋死吧
409 请求冲突。由于和被请求的资源的当前状态之间存在冲突,请求无法完成
410 遗失的。被请求的资源在服务器上已经不再可用,而且没有任何已知的转发地址
413 响应实体太大。服务器拒绝处理当前请求,请求超过服务器所能处理和允许的最大值
417 期望失败。在请求头 Expect 中指定的预期内容无法被服务器满足
418 我是一个茶壶。超文本咖啡罐控制协议,但是并没有被实际的HTTP服务器实现
420 方法失效
422 不可处理的实体。请求格式正确,但是由于含有语义错误,无法响应
500 服务器内部错误。服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理
HTTP请求方法
HTTP 设计了很多动词,来表示不同的操作
先来解释一个概念,幂等性,指一次和多次请求某一个资源应该具有同样的副作用,也就是一次访问与多次访问,对这个资源带来的变化是相同的。
常用的动词及幂等性
| 动词 | 描述 | 是否幂等 |
|---|---|---|
| GET | 获取资源,单个或多个 | 是 |
| POST | 创建资源 | 否 |
| PUT | 更新资源,客户端提供完整的资源数据 | 是 |
| PATCH | 更新资源,客户端提供部分的资源数据 | 否 |
| DELETE | 删除资源 | 是 |
GET和POST的区别
本质上来说,GET用于查询,POST用于修改。
- GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码.
表面的区别
-
GET在浏览器回退时是无害的,而POST会再次提交请求。
-
GET产生的URL地址可以被保存为书签,而POST不可以。
-
GET请求会被浏览器主动cache,而POST不会,除非手动设置。
-
GET请求只能进行url编码,而POST支持多种编码方式。
-
GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
-
get方式提交数据的大小(一般来说1024字节),http协议并没有硬性限制,而是与浏览器、服务器、操作系统有关,而POST理论上来说没有大小限制,http协议规范也没有进行大小限制,但实际上post所能传递的数据量根据取决于服务器的设置和内存大小。
-
对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
-
GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
-
GET请求在URL中传送的参数是有长度限制的,而POST通过Body传送数据,长度没有限制。
没有区别的回答
GET和POST是HTTP协议中的两种发送请求的方法。
HTTP是基于TCP/IP的关于数据如何在万维网中如何通信的协议。
HTTP的底层是TCP/IP。所以GET和POST的底层也是TCP/IP,也就是说,GET/POST都是TCP链接。GET和POST能做的事情是一样一样的。你要给GET加上request body,给POST带上url参数,技术上是完全行的通的。
GET和POST本质上就是TCP链接,并无差别。但是由于HTTP的规定和浏览器/服务器的限制,导致他们在应用过程中体现出一些不同
重大区别
GET产生一个TCP数据包;POST产生两个TCP数据包。
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
因为POST需要两步,时间上消耗的要多一点,看起来GET比POST更有效。因此Yahoo团队有推荐用GET替换POST来优化网站性能。但这是一个坑!跳入需谨慎。
-
GET与POST都有自己的语义,不能随便混用。
-
据研究,在网络环境好的情况下,发一次包的时间和发两次包的时间差别基本可以无视。而在网络环境差的情况下,两次包的TCP在验证数据包完整性上,有非常大的优点。
-
并不是所有浏览器都会在POST中发送两次包,Firefox就只发送一次。
看了这么多,是不是会觉得一脸懵逼,在你做项目的时候要注意:
get一般是用来获取数据,post提交数据
post其实是有大小限制的,只不过是取决于服务器的设置和内存大小。
还有更深入的区别:
GET是用来向获取服务器信息的,请求报文传输的信息只是用于描述所需资源的参数,返回的信息才是数据本身;POST是用来向服务器传递数据的,其请求报文传递的信息就是数据本身,返回的报文只是操作的结果。